Scaling Laws and Superposition
Update (July 2024): A formal version of this work is now on arXiv.
Abstract
Using results from scaling laws, this short note argues that the following two statements cannot be simultaneously true:
- Superposition hypothesis where sparse features are linearly represented across a layer is a complete theory of feature representation.
- Features are universal, meaning two models trained on the same data and achieving equal performance will learn identical features.
Introduction
Scaling laws
where $N_c$, $D_c$, $\alpha_N$, and $\alpha_D$ are constants for a given task such as Language modeling
The scaling laws are not mere empirical observations and can be seen as a predictive laws on limits of language model performance. During training of GPT-4,
OpenAI
An important detail is that the relation is expressed in terms of the number of parameters.
It's natural to think of a model's computational capacity in terms of parameters, as they are the fundamental independent variables that the model can tune during learning.
The amount of computation that a model performs in FLOPs for each input is also estimated to be $2N$
Let's compare this with Interpretability, where the representation of a feature is defined in terms of neurons or groups of neurons
In this paper, we assume the above to be true and consider the number of parameters to be the true limiting factor, and we can achieve similar model performance for a
range of aspect ratios. We then apply this as a postulate to the superposition hypothesis
The superposition hypothesis states that models can pack more features than the number of neurons they have. There will be interference between the features as they can't be represented orthogonally, but when the features are sparse enough, the benefit of representing a feature outweighs the cost of interference. Concretely, given a layer of activations of $m$ neurons, we can decompose it linearly into activations of $n$ features, where $n$ > $m$, as:
where $activation_{layer}$ and $W_{f_i}$ are vectors of size $m$, and $x_{f_i}$ represents the magnitude of activation of the $i$-th feature. Sparsity means that for a given input, only a small fraction of features are active, which means $x_{f_i}$ is non-zero for only a few values of $i$.
Case study on changing Aspect Ratio
Let's consider two models, Model A and Model B, having the same macroscopic properties. Both have an equal number of non-embedding parameters,
are trained on the same dataset, and achieve similar loss according to scaling laws. However, their shape parameters differ. Using the same notation
as Kaplan et al.
The total number of neurons in a model is calculated by multiplying the number of neurons per layer by the number of layers. As a result, Model B has half the total number of neurons compared to Model A.
Now, let's apply the superposition hypothesis, which states that features can be linearly represented in each layer. Since both models achieve equal loss on the same dataset, it's reasonable to assume that they have learned the same features. Let's denote the total number of features learned by both models as $F$.
The above three paragraphs are summarized in the table below:
| Model A | Model B | |
|---|---|---|
| Total Parameters | $d_{model}^2n_{layer}$ | $d_{model}^2n_{layer}$ |
| Neurons per Layer | $d_{model}$ | $2d_{model}$ |
| Number of Layers | $n_{layer}$ | $\frac{n_{layer}}{4}$ |
| Total Number of Neurons | $d_{model}n_{layer}$ | $\frac{d_{model}n_{layer}}{2}$ | Total Number of Features Learned | $F$ | $F$ |
| Number of Features per Layer | $\frac{F}{n_{layer}}$ | $\frac{4F}{n_{layer}}$ |
| Features per Neuron | $\frac{F}{d_{model}n_{layer}}$ | $\frac{2F}{d_{model}n_{layer}}$ |
The average number of features per neuron is calculated by dividing the number of features per layer by the number of neurons per layer. In Model B, this value is twice as high as in Model A, which means that Model B is effectively compressing twice as many features per neuron, in other words, there's a higher degree of superposition. However, superposition comes with a cost of interference between features, and a higher degree of superposition requires more sparsity.
Elhage et al.
So Model B, with higher degree of superposition, should have sparser features compared to Model A. But, sparsity of a feature is a property of the data itself, and the same feature can't be sparser in Model B if both models are trained on the same data. This might suggest that they are not the same features, which breaks our initial assumption of two models learning the same features. So either our starting assumption of feature representation through superposition or feature universality needs revision. In the next section, we discuss how we might modify our assumptions.
Discussion
To recap, we started with the postulate that model performance is invariant over a wide range of aspect ratios and arrived at the inconsistency between superposition and feature universality. Though we framed the argument through the lens of superposition, the core issue is that the model's computational capacity is a function of parameters where as model's representational capacity is a function of total neurons.
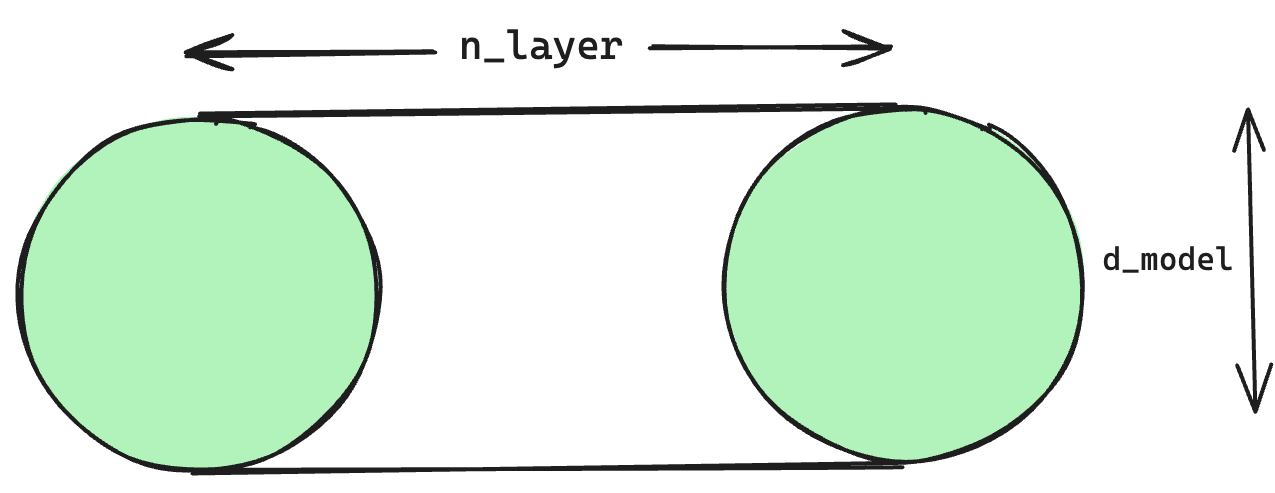
A useful, though non-rigorous analogy, is to visualise a solid cylinder of radius $d_{model}$ and height $n_{layer}$. The volume (parameters) of the cylinder can be thought of as computational capacity whereas features are represented on the surface (neurons). We can change the aspect ratio of the cylinder while keeping the volume constant by stretching or squashing it. This changes the surface area accordingly. Though this analogy doesn't include sparsity, it captures the essentials of the argument in a simple way.
Coming to solutions, I do not have one that's consistent with scaling laws, superposition hypothesis and feature universality, but will speculate on what a possible one might look like.
Schemes of Compression Alternative to Superposition: A crude and simple way to convert the total number of features into a function of parameters is to add a square term to compressed sensing bounds so it becomes $n = m^2.f(1-S)$ . But this would require a completely new compression scheme compared to superposition. Methods such as Dictionary learning which disentangle features assuming superposition hypothesis have been successful for extracting interpretable features. So it's not ideal to ignore it, representation schemes whose first-order approximation looks like superposition might be more viable.
This isn't to say there's nothing we can improve on in the superposition hypothesis. Although dictionary learning features in
Bricken et al.
Cross Layer Superposition: Previously, we used to look for features in a single neuron
Acknowledgments
I'm thankful to Jeffrey Wu and Tom McGrath for their helpful feedback on this topic. Thanks to Vinay Bantupalli for providing feedback on the draft. Any mistakes in content or ideas are my own, not those of the acknowledged.
Earlier version of this work was supported by an Open Philanthropy research grant.
This article was prepared using the Distill Template.
Citation Information
Please cite this work as:
@article{katta2024implications,
title={On Implications of Scaling Laws on Feature Superposition},
author={Pavan Katta},
year={2024},
journal={arXiv preprint arXiv:2407.01459},
url={https://arxiv.org/abs/2407.01459}
}